이번 포스팅은 일자별로 적재된 타자, 투수 데이터를 주별 최우수 선수를 가려내기 위한 주별 데이터로 변환해보려고한다.
주별 집계를 하기전 필요한 지표부터 추려봤다.
타자의 경우는 타석, 타수, 득점, 안타, 홈런, 타점, 볼넷, 데드볼, 삼진, 땅볼아웃, 병살타, 타율 등등의 기록을 주차별로 집계할것이고
투수의 경우는 그날의 등판 기록 (ex. 승,패,홀,세) , 이닝, 상대한 타자 수 , 피안타, 실점, 자책점, 볼넷, 데드볼, 삼진 피홈런의 기록을 집계할것이다.
우선 타자, 투수 데이터를 불러와보자
conn = pymysql.connect(host = host, user = user, passwd=passwd, db = db, charset='utf8', port = port,cursorclass=pymysql.cursors.DictCursor)
cur = conn.cursor()
sql = '''select * from batting_info
'''
cur.execute(sql)
result = cur.fetchall()
batting = pd.DataFrame(result)
sql = '''select * from pitching_info
'''
cur.execute(sql)
result = cur.fetchall()
pitching = pd.DataFrame(result)
conn.close()타자, 투수 각각 batting, pitching 데이터프레임에 저장해두고 isocalendar 모듈을 사용하여 week 컬럼을 만들었다.
batting['week'] = batting['yyyymmdd'].astype(str).apply(lambda x : x[0:4] + str(datetime.strptime(x[0:4] + '-'+ x[4:6]+'-'+x[6:8] ,'%Y-%m-%d').isocalendar().week))
pitching['week'] = pitching['yyyymmdd'].astype(str).apply(lambda x : x[0:4] + str(datetime.strptime(x[0:4] + '-'+ x[4:6]+'-'+x[6:8] ,'%Y-%m-%d').isocalendar().week))그런다음에 week, player_name, player_birth, team을 기준으로 groupby를 했다.
# 주별 합산 지표 컬럼만 추리기
batting_week = batting.groupby(['week','player_name','player_birth','team']).sum()[['TPA','AB','R','H', 'HR','RBI','BB', 'HBP','SO','GO','FO','PIT','GDP','LOB']].reset_index()
pitching_week = pitching.groupby(['week','player_name','player_birth','team']).sum()[['today_type','IP','TBF','H','R','ER','BB','HBP','K','HR']].reset_index()별 문제없이 groupby가 되어서 데이터를 확인해봤다.

뭔가 이상한점이 하나 있었다. IP는 이닝을 의미하고 소수점은 아웃카운트를 의미하는데 578번 인덱스의 한현희 선수의 데이터를 보면 6.3이닝으로 되어있었다. 분명 6.3이닝이 아닌 7이닝으로 되어야하는데 ..
확인해보니 일별데이터가 소수로 되어있고 이걸 그대로 sum하는과정에서 발생한 문제였었다. 이 문제를 해결하기 위해서는 소수부분과 정수부분을 나눠서 집계를 해야했다.
pitching['IP2'] = pitching['IP'].astype(str).apply(lambda x : int(x.split('.')[1]))
pitching['IP'] = pitching['IP'].astype(str).apply(lambda x : int(x.split('.')[0]))IP2라는 컬럼을 새로 만들어서 소수부분을 담아둔 후 다시 집계를 진행했다.

분리가 정상적으로 되었다. 이제 IP2의 데이터를 3으로 나눈 몫을 이닝에 더해주고 나머지를 소수점에 붙여주기만 하면된다!
pitching_week['IP'] = pitching_week['IP'] + pitching_week['IP2'].apply(lambda x : x//3) + pitching_week['IP2'].apply(lambda x : x%3/10)
타자쪽은 주별 집계로 만들어진 타율은 정확한 타율이 아니므로 타수와 안타의 개수로 타율계산을 해줬다.
batting_week['AVG'] = batting_week['H']/batting_week['AB']
batting_week['AVG'] =batting_week['AVG'].fillna(0.0)
데이터 검증
이제 데이터 검증을 해보자 간단하게 23년도 13주차의 최고의 타율을 기록한 선수를 찾아봤는데
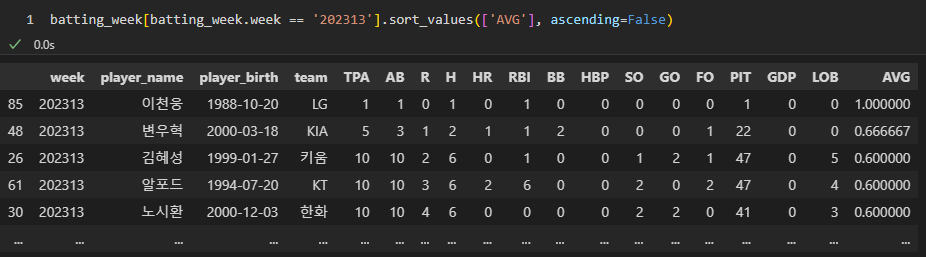
이천웅 선수가 나왔다. 데이터로서는 10할의 타자지만, 데이터 표본이 적은선수의 기록은 의미있는 기록이 아니었다.
그래서 타석수가 너무 적은 타자들은 포함시키지 않기 위해서 어떻게 해야할까 고민해봤는데 실제 야구 데이터 기록에서도 사용되는 규정 타석, 규정 이닝을 도입하기로 했다.
규정 타석이란, 유자격자를 결정하기 위해 최소 타석수로 너무 표본이 적은 선수를 걸러내기 위한 기록체계이다.
규정 이닝도 비슷하게 최소 이닝수를 정하는것이다.
규정 타석을 도입하기 위해서는 해당 주차의 소속팀의 경기수가 필요했다.
타자 기록이 있으면 경기가 있었다고 가정하고 타자기록을 사용했다.
# 규정 타석, 이닝을 계산하기위한 주별 팀 경기수 변수 생성
team_games = batting.groupby(['week','team','yyyymmdd']).count().reset_index()
team_games = team_games.groupby(['week','team']).count().reset_index()[['week','team','yyyymmdd']]
team_games['game_count'] = team_games['yyyymmdd']
team_games = team_games[['week','team','game_count']]이제 이 데이터프레임을 각각의 데이터에 병합해주고 규정타석, 이닝을 계산했다.
batting_week = batting_week.merge(team_games, on = ['week', 'team'], how = 'left')
pitching_week = pitching_week.merge(team_games, on = ['week', 'team'], how = 'left')
# 타자 규정타석 경기수 * 3.1
batting_week['RTPA'] = batting_week['game_count']*3.1
batting_week = batting_week[['week', 'player_name', 'player_birth', 'team', 'TPA','RTPA', 'AB', 'R', 'H',
'HR', 'RBI', 'BB', 'HBP', 'SO', 'GO', 'FO', 'PIT', 'GDP', 'LOB',
'AVG','game_count']]
# 투수 규정 이닝 경기수 * 1
pitching_week['RIP'] = pitching_week['game_count'] * 1.0이제 선수마다의 규정타석을 컬럼으로 저장해두었기 때문에 좀 더 가치있는 기록을 확인할 수 있다.

이제 데이터를 DB로 넣어주기만 하면된다.
engine = create_engine(f"mysql+pymysql://{user}:{passwd}@{host}:{port}/{db}?charset=utf8")
conn = engine.connect()
batting_week.to_sql(name = 'weekly_batting_info', con = engine, if_exists = 'append', index=False)
conn.close()
engine = create_engine(f"mysql+pymysql://{user}:{passwd}@{host}:{port}/{db}?charset=utf8")
conn = engine.connect()
pitching_week.to_sql(name = 'weekly_pitching_info', con = engine, if_exists = 'append', index=False)
conn.close()
마치며
이번에 집계를 하면서 예상치 못한 것들이 많이 발견되었다. 이닝은 소수인데 테이블 컬럼 정수형으로 해서 데이터를 다시 수집하거나 이닝을 합치면서 소수점이 이상하게 된다던지.. 그래도 그렇게 심각한 문제는 아니어서 금방 해결했던 것 같다.
다만 today_type컬럼에 승,패 이런 문자들이 합쳐져서 나오는데 이걸 분리해야할지 그대로 가져가도 될지 고민이다...
아무튼 다음 포스팅은 주간 데이터 집계를 DAG로 만들어서 자동화하는 과정을 다뤄보려고한다!
'Data' 카테고리의 다른 글
| 크롤링 데이터 전처리(naver) (0) | 2023.07.11 |
|---|---|
| 크롤링 데이터 전처리 (2) (0) | 2023.05.03 |
| 크롤링 데이터 전처리 (1) (0) | 2023.04.25 |