크롤링 데이터 전처리 (1)
이번 포스팅은 statiz에서 크롤링해서 가져온 데이터를 전처리해보려고한다.
크롤링은 urllib.request 모듈을 사용해서 진행했다. selenium을 사용하지 않는 이유는 아래 포스팅에 있다!
2023.04.16 - [Docker] - Docker 환경에서 크롤링하기
Docker 환경에서 크롤링하기
야구 데이터를 지속적으로 얻기 위해서 http://www.statiz.co.kr/main.php 사이트에서 경기 정보를 크롤링하여 데이터를 적재하는 DAG를 작성하는과정중 예상치 못한 문제가 발생했다. 크롤링을 제대로
developer-trainee-j.tistory.com
크롤링을 하기 위해서는 내가 원하는 데이터가 있는 url주로를 알아야한다.
일자별 데이터가 필요했고, 일일 기록이 있는 페이지는 statiz - 경기일정 에서 경기를 클릭한 후 박스스코어를 클릭해야했다. 예시 주소는 다음과 같다
STATIZ
이름PTPAABRHHR RBIBBHBPSOGOFO PITGDPLOBAVGOPSLIWPARE24 1홍창기75311002011028000.3100.8920.880.0410.542문성주95302002000119010.4381.0161.430.1110.67신민재r9000000000000000.0000.000-0.142-0.663김현수05502010001211040.3430.8541.56-0.0060.324오
www.statiz.co.kr
기본적으로 http://www.statiz.co.kr/boxscore.php? 주소에서 출발하며 opt = {month}, date = {경기날짜}, stadium = {경기장} hour = {경기시간} 이렇게 4가지의 파라미터가 필요했다. opt와 date는 어차피 날짜기준으로 크롤링을 진행하기때문에 큰 문제는 없었지만 경기장과 경기시간은

이 화면에서 나와있지 않았다.. 하지만 크롤링 후 "boxscore.php?date={now}&" 기준으로 split을 한 뒤 뒤에서부터 5개의 데이터를 보니까 경기 요일 박스안에 'stadium=%EA%B3%A0%EC%B2%99%EB%8F%94&hour=18"><span class="badge" style= ....
이런식으로 경기시간과 경기장이 있어서 이 데이터를 활용해서 경기별 url주소를 만들어보기로 했다.
# 크롤링 사이트
target_url = f'http://www.statiz.co.kr/schedule.php?opt={month}&sy=2023'
html = urllib.request.urlopen(target_url).read()
bsObject = BeautifulSoup(html, 'html.parser')
# 캘린더 화면에서 요일의 경기 데이터 가져오기 위한 split
init_url = str(bsObject.find_all('table', {'class' : 'table table-striped table-bordered'})).split(f'boxscore.php?date={now}&')[-5:]
batting = pd.DataFrame()
pitching = pd.DataFrame()
hometeam_list = ['-']
# 경기마다 하나씩 출력
for i in init_url:
# 크롤링 가능 주소인지 확인하는 로직
if i[:8] == 'stadium=':
print('=' * 50)
stadium = str(i).split('>')[0]
url = f'http://www.statiz.co.kr/boxscore.php?opt=4&date={now}&{stadium}'
html = urllib.request.urlopen(url).read()
bsObject = BeautifulSoup(html, 'html.parser')
만약 init_url에 들어있는 정보 중 stadium으로 시작하지 않는 경우를 회피하기 위해서 if문을 걸어두고 필요한 정보를 잘라내야했다. 공통적으로 '>'으로 끝나는 것을 확인해서 '>'기준으로 데이터를 잘라준 후 url에 붙여서 크롤링을 진행했다.
이 과정을 완료하면 이제 사용할 데이터가 있는 화면이 나온다
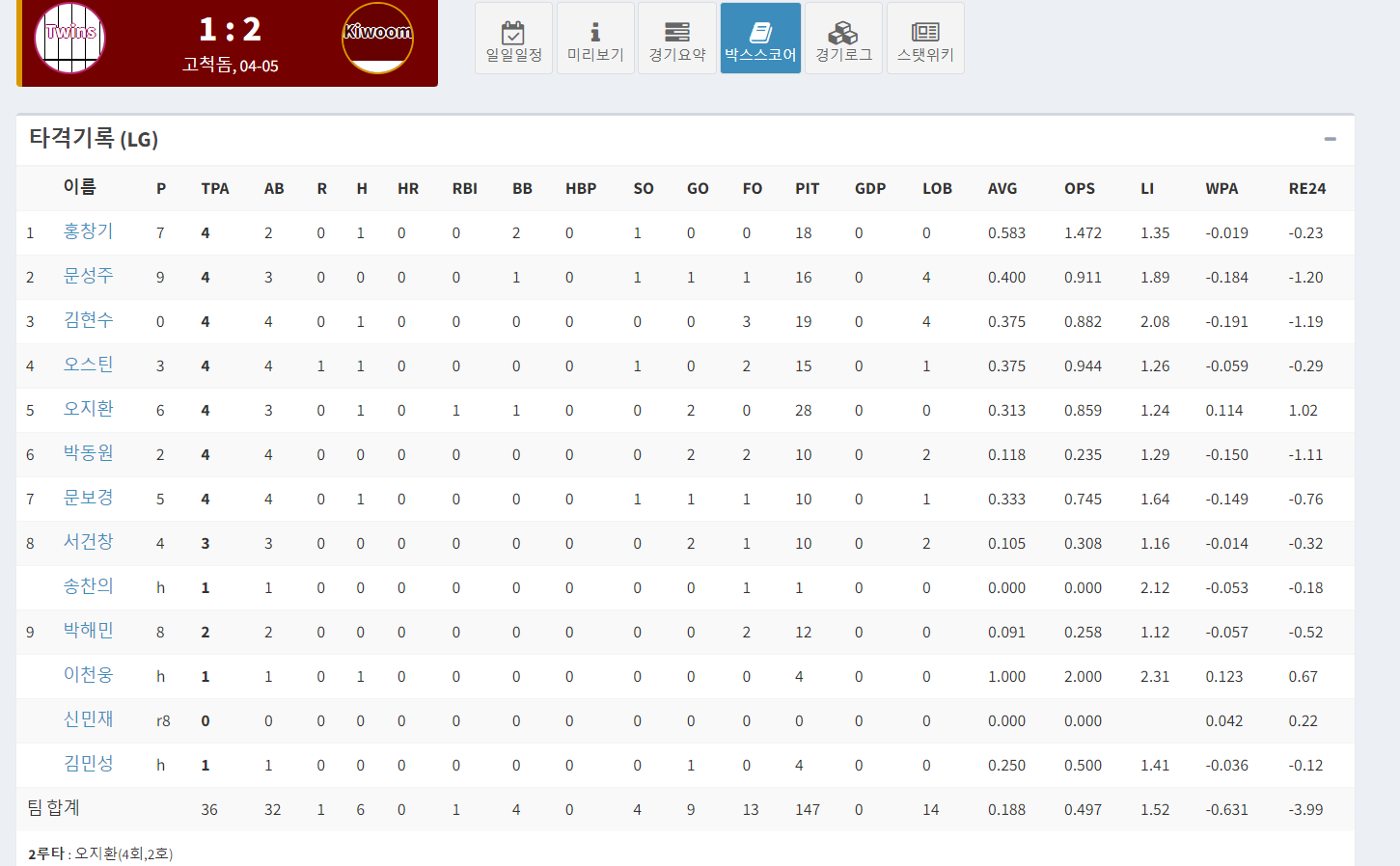
bsObject 객체를 프린트해서 데이터를 찾아본 결과
# 홈팀
home_batting = str(bsObject.find_all('h3')[1])
hometeam = home_batting.split('(')[1].split(')')[0]
# 원정팀
away_batting = str(bsObject.find_all('h3')[2])
awayteam = away_batting.split('(')[1].split(')')[0]<h3> element의 1번 인덱스에 홈팀이름이 있었고 2번 인덱스에는 원정팀이름이 있었다. 이 정보도 필요하므로 우선 변수에 저장해뒀다.
홈팀의 table 정보는 <th> element에서 타격데이터의 컬럼값을 추출한 뒤
<table> element 3번 인덱스에서 선수별 타격정보를 리스트형태로 저장했다. 그 후 df 형식으로 만들기 위해 2차원 배열로 만드는 함수를 거친 후 데이터를 df형식으로 변환했다. 원정팀은 <table> 5번 인덱스에서 진행했다.
투수정보는 <table> 7번과 9번 인덱스를 사용했다.
컬럼 데이터 추출
batting_columns = ['yyyymmdd', 'player_name', 'player_birth', 'team']
for i in bsObject.find_all('th')[2:22]:
batting_columns.append(str(i).split('<th>')[1].split('</th>')[0])
############################
## 홈팀 데이터 추출 진행 ! ##
############################
# 홈팀 타자들의 정보 리스트로 담아두기
home_batting_list = []
for i in str(bsObject.find_all('table')[3]).split('birth=')[1:]:
home_batting_list.append(i)
# 타자별 정보 분리 및 2차월 배열로 저장
home_player_list = transform_batting_data(home_batting_list, hometeam)
home_team_battingfor문 마다 경기하나씩 홈팀 원정팀 df가 만들어지고 for문 밖에서 선언한 batting, pitching 데이터프레임에 하나씩 concat을 시켰다.

이제 이 데이터프레임을 각각의 테이블에 to_sql형식으로 밀어줬다.
# db 정보 가져오기
host = info['MARIADB']['IP']
user = info['MARIADB']['USER']
passwd=info['MARIADB']['PASSWD']
db = info['MARIADB']['DB']
port = info['MARIADB']['PORT']
##############################
######### 데이터 적재 #########
##############################
# [타자] to_sql로 밀어넣기
engine = create_engine(f"mysql+pymysql://{user}:{passwd}@{host}:{port}/{db}?charset=utf8")
conn = engine.connect()
batting.to_sql(name = 'batting_info', con = engine, if_exists = 'append', index=False)
conn.close()
# [투수] to_sql로 밀어넣기
engine = create_engine(f"mysql+pymysql://{user}:{passwd}@{host}:{port}/{db}?charset=utf8")
conn = engine.connect()
pitching.to_sql(name = 'pitching_info', con = engine, if_exists = 'append', index=False)
conn.close()**to_sql 방식은 데이터 프레임을 바로 db에 넣을 수 있는 대신 컬럼의 순서와 형태가 맞아야한다
이렇게하면 이제 지정된 날짜의 경기데이터를 크롤링하여 바로 db에 넣을 수 있는 코드가 완성된다.
마치며
예전에 네이버 지도 크롤링을 해본적이 있었는데 그때는 xpath를 활용하여 정보가 있는 element를 특정했었다.
request방식으로 데이터를 긁어서 하나하나 찾아보는데 생각보다 양이 너무 많아서 눈이 너무 아팠다..
그래도 데이터가 정상적으로 가져와지고 적재까지 되어서 너무 다행이다. 간혹 경기데이터가 비어있는 경우가 있어서
야구경기가없는 월요일이나 월이 끝난 후 전체 데이터를 적재하는 배치를 하나 만들어야겠다.
다음 포스팅은 적재된 데이터를 바탕으로 player 테이블을 구성해보려고한다.